FormantStat: 포먼트 통계 도구 모음
english
| 프로젝트 개요
| 다운로드
FormantStat-0.2 Released!
Java를 설치하세요!
자바 까셨습니까? FormantStat를 실행하기 위해서는 컴퓨터에 Java Runtime Environment가 설치되어 있어야 합니다.
JRE 버전 5.0을 설치하세요.
Root Data
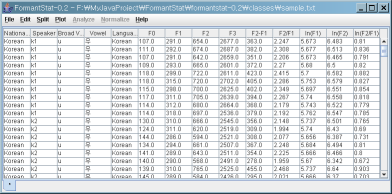
처음 파일을 불러오면 "*"이라고 이름이 붙은 "Root" 데이터 테이블이 생깁니다. "*"은 모든 자료를
포함하고 있다는 의미입니다. 데이터 파일이 어떻게 생겼는지 보고 싶으시면 sample.txt을
클릭해서 확인하세요. 데이터 파일이 어떤 형식을 가져야 하는지 아래 내용을 읽어보세요.
- 데이터 파일은 탭으로 구분된 텍스트 파일입니다.
- 필드(=열)은 탭으로 구분되어 있고 레코드(=줄)은 엔터로 구분되어 있어야 합니다.
- 데이터에 ASCII 이외의 문자가 포함되어 있는 경우:
- 파일을 저장하실 때 인코딩을 UTF-8으로 하셔야 합니다.
- 이때 BOM은 넣지 마세요.
- ASCII 문자는 영문자와 숫자 그리고 일반 키보드에 있는 구두점과 기호들을 말합니다.
여러분의 데이터 파일에 한글이 포함되어 있다면 반드시 UTF-8으로 저정하셔야 합니다.
- 파일의 첫 줄에는 필드(=열)의 이름이 있어야 합니다.
- 필드 중에서 수치가 아닌 데이터가 포함된 경우에는 이름 맨 뒤에 $ 기호를 붙여주세요.
- 예를 들어, "Nationality$", "Speaker$", "Vowel$".
- 다음 4 필드는 반드시 있어야 합니다: "Speaker$", "Vowel$", "F1", "F2".
- 여러분 데이터에 이 네가지 정보 중 필요 없는 것이 있다고 하더라도 반드시 이 4 필드는 있어야 합니다.
- 그런 경우에 빈 열을 만들어 주세요. "Speaker$"나 "Vowel$"에는 "null"을 채우고 "F1"과 "F2"에는 "0"를 채우시면 됩니다.
- 예를 들어 여기를 눌러 보세요.
- 그 이외의 다른 열은 얼마든지 자유롭게 포함시키실 수 있습니다.
Splitter: Splits into sub tables
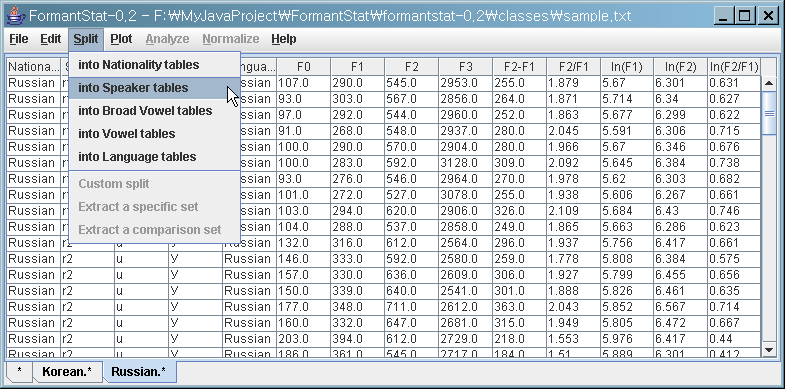
메뉴바에서 "Split" 메뉴를 눌러 보세요. 현재 열러 있는 데이터 테이블의 필드 이름들을 보실 수 있습니다.
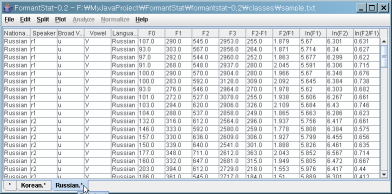
(1) 현재 선택되어 있는 "Root" 데이터를 "Nationality"에 따른 테이블로 나누어 보겠습니다.
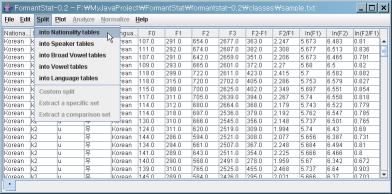
(2) 아래와 같이 "Korean.*"과" Russian.*"이라는 이름이 붙은 새로운 테이블이 생긴 것을 보실 수 있습니다.
"Korean.*"은 모든 "Korean"의 데이터라는 의미라고 생각하시면 됩니다.

(3) 이제 "Russian" 테이블을 선택해 보겠습니다.
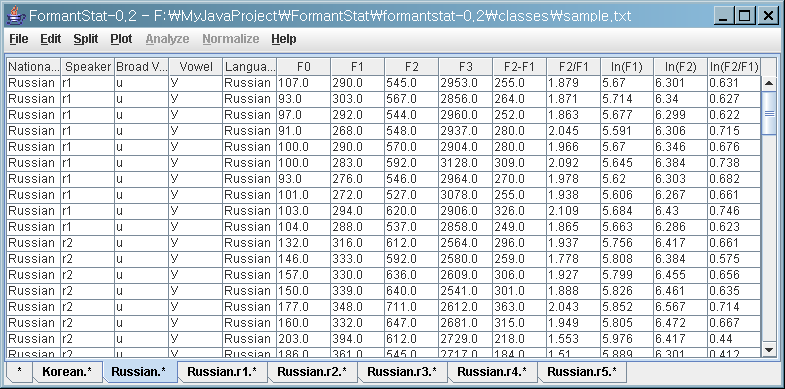
(4) 그리고 "Russian" 테이블을 "Speaker"에 따른 테이블로 잘라보겠습니다.
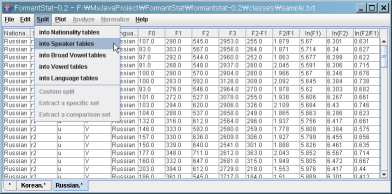
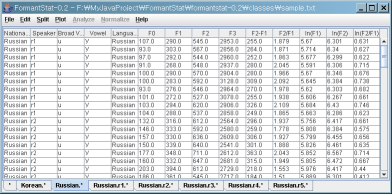
(5) 새로운 테이블이 5개 생긴 것을 보실 수 있습니다.
"Russian.r1.*", "Russian.r2.*", 등으로 이름이 붙어있습니다.
"Russian.r1.*"이라는 것은 "Russian" 화자 "r1"의 모든 데이터라는 의미로 생각하시면 됩니다.
[TOP]
Plotter:
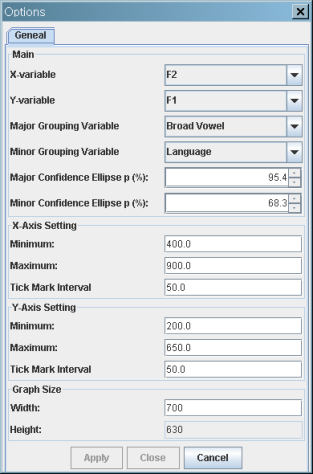
신뢰타원이 있는 산점도를 그려줍니다.
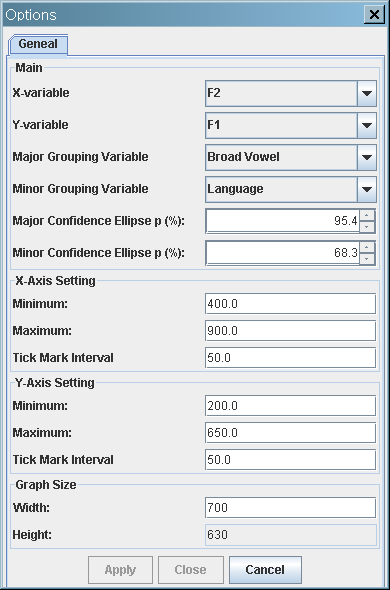
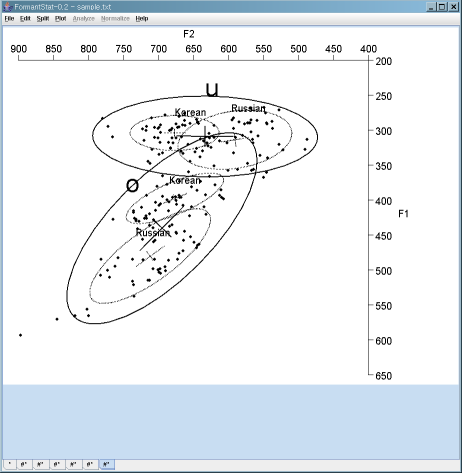
F2 vs. F1 scatterplot with confidence ellipses
- Major confidence ellipses: Two "Broad Vowels":
- /u/ is a collapsed vowel of Korean /우/ and Russan /у/;
- /o/ is a collapsed vowel of Korean /오/ and Russian /о/.
- Minor confidence ellipses: Korean vs. Russain
[TOP]
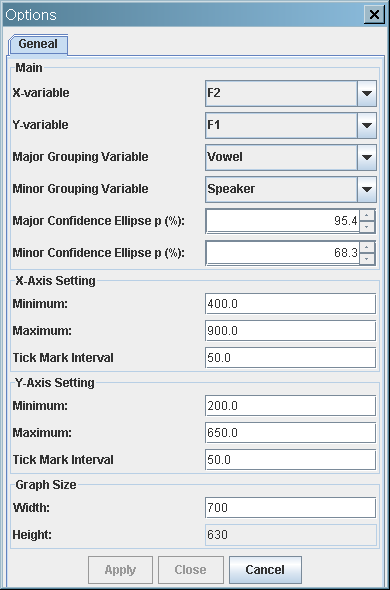
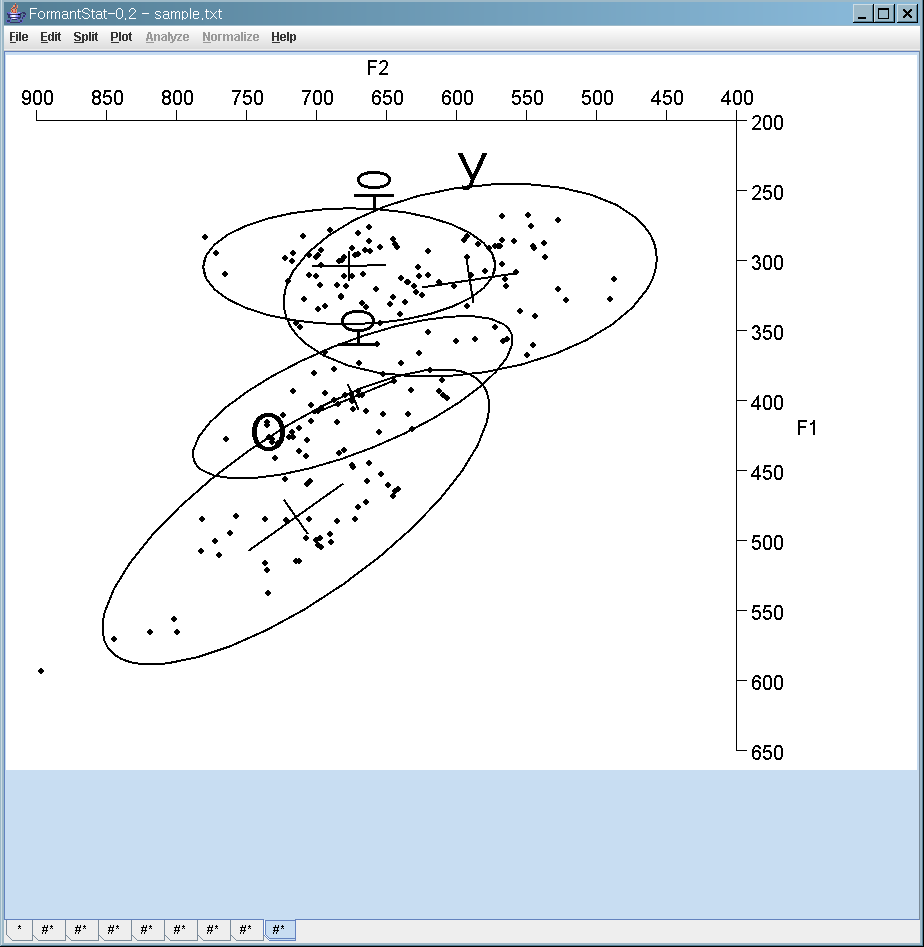
F2 vs. F1 scatterplot with confidence ellipses
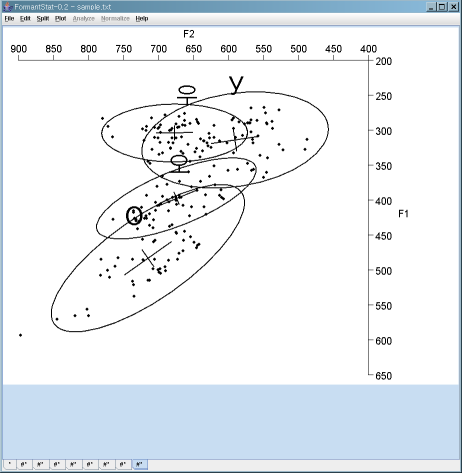
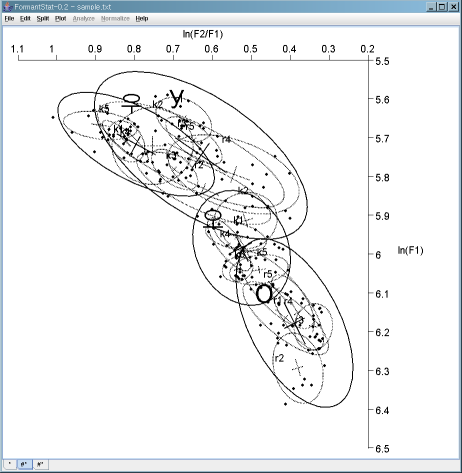
- Major confidence ellipses: Four "Vowels" - Korean /우/ and Russian /у/; Korean /오/ and Russian /о/
- Minor confidence ellipses: Five Korean and five Russian Speakers. Each minor confidence ellipse bounds five minor speaker ellipses.

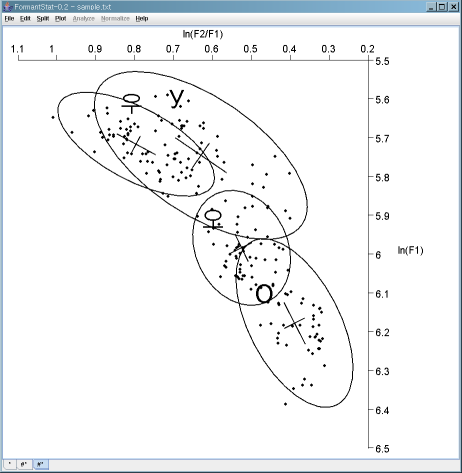
You can draw major ellipses without minor ellipse:
[TOP]
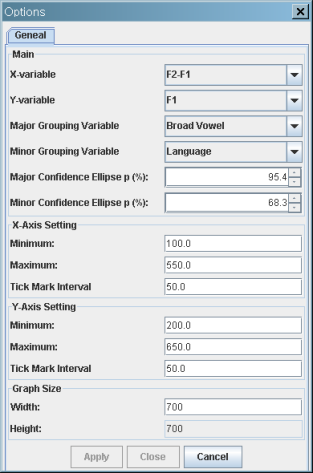
F2-F1 vs. F1 scatterplot with confidence ellipses
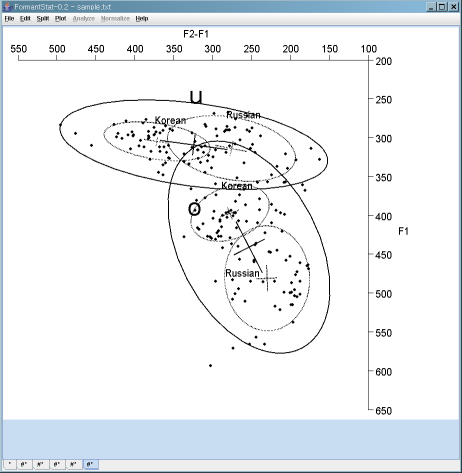
[TOP]
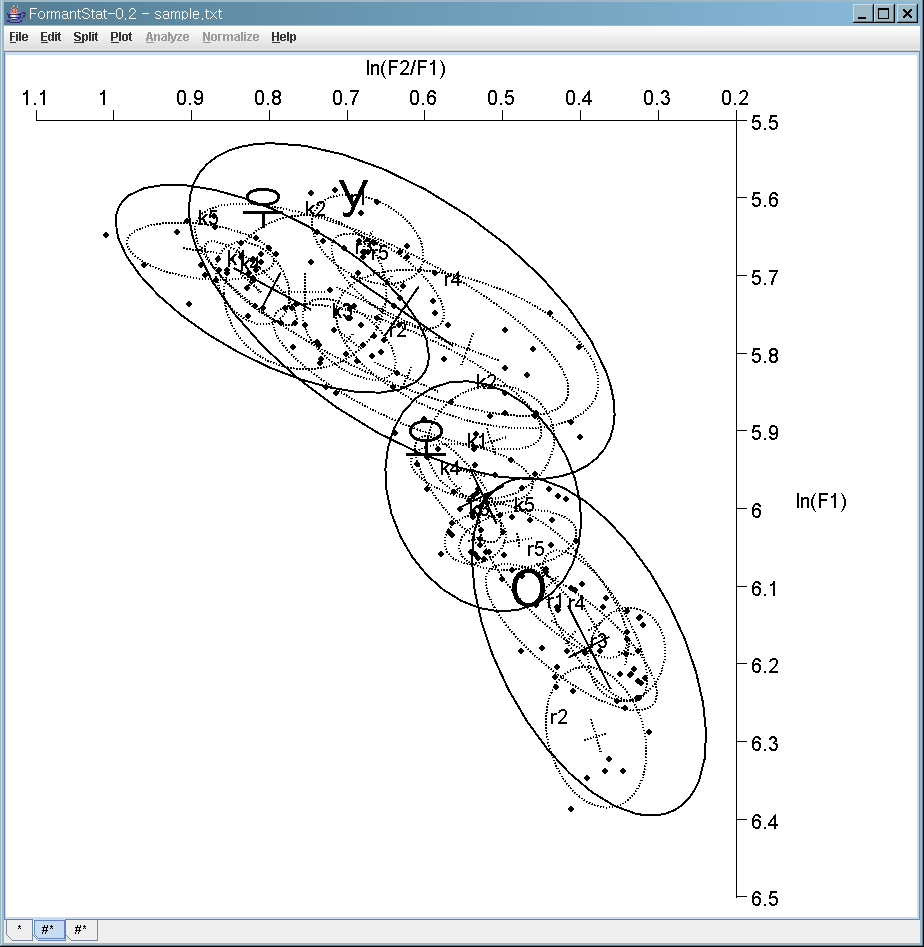
ln(F2/F1) vs. ln(F1) scatterplot with confidence ellipses
The natural logairthm ln is the logarithm having base e = 2.7182...

Without minor ellipse:
[TOP]
ln(F2/F1) vs. ln(F1) scatterplot with confidence ellipses


Analyzer: basic statistics and more
Not yet implemented!
Noramlizer: speaker normalization
Not yet implemented!