FormantStat: Tools for Formant Statistics
|

|
korean
| summary
| downloads
FormantStat-0.2 Released!
- Root Data: tabbed text file (UTF-8, no BOM) containing Speaker, Vowel, F1, F2 columns and any other columns.
- Splitter: Splits a formant data table into categorized minor tables.
- Plotter: Draws a scatterplot of formant pairs with and without confidence ellipses.
- Analyzer: Not implemented!
- Normalizer: Not implemented!
Do you have Java installed on your computer?
You need JRE (java runtime environment) to run the FormantStat.
Download and install JRE at java.sun.com.
Root Data
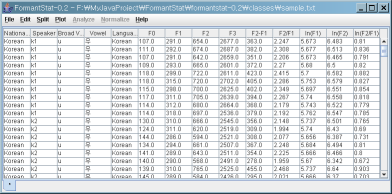
The "Root" data table is automatically named "*", everything. Click sample.txt
to see how looks like the data file (tabbed txt, utf8, no BOM).
- The data file is a tabbed text file. Fields(=columns) are splitted by TAB and records(=rows) are splitted by ENTER.
- If the data contains non-ASCII characters (simply, non-english alphabets), the file should be saved as UTF-8 encoding without BOM.
- The first line of the file should contains the column(=field) names.
- The names of columns containing strings (not numeric values) should have the suffix $.
- For example, "Nationality$", "Speaker$", "Vowel$".
- The data file should contains the following four columns: "Speaker$", "Vowel$", "F1", "F2".
- Even if you don't have such data, you should have the four columns.
- Please fill "0" for F1 or F2 column and "null" for Speaker or Vowel column like this.
- The data file may contains any other data columns.
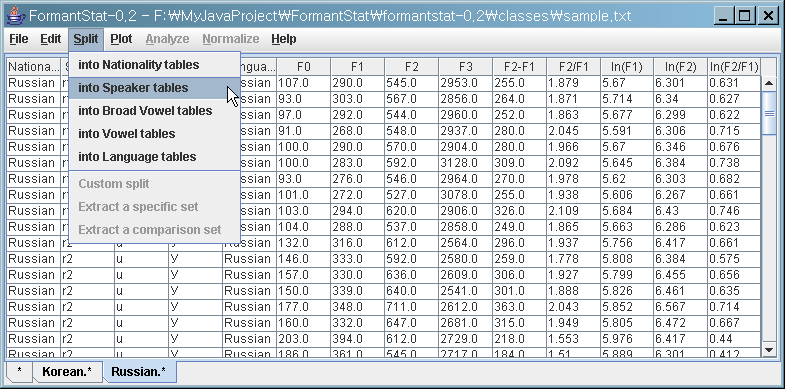
Splitter: Splits into sub tables
Click on the "Split" menu and you can see the list of string columns.
(1) Split the current "Root" data table into "Nationality" tables
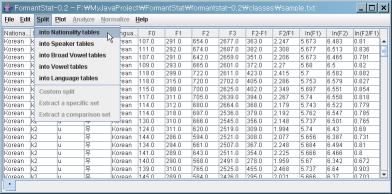
(2) You can see two new tabs created: "Korean.*" and "Russian.*", i.e. all Korean data and all Russian data.

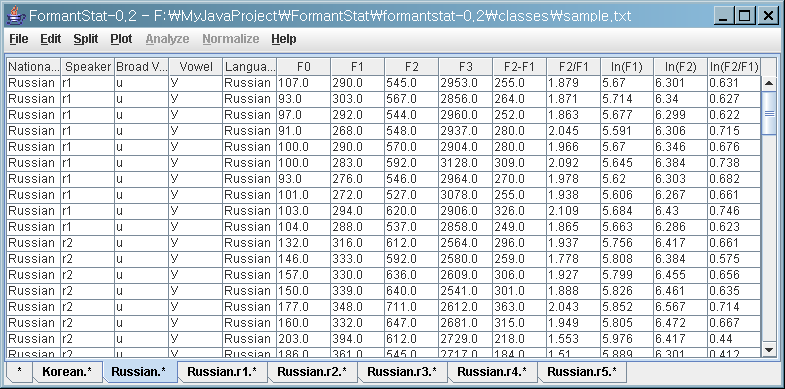
(3) Select the "Russian" table
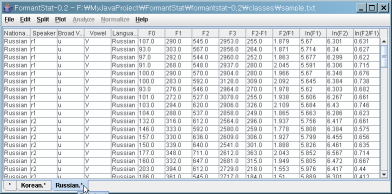
(4) Split the "Russian" tables into "Speaker" tables.
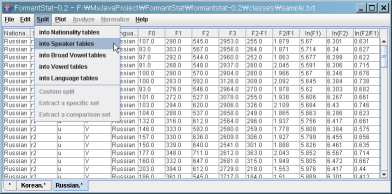
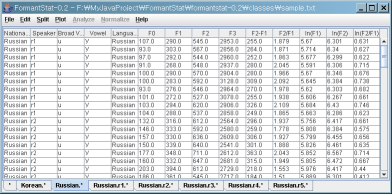
(5) You can see new tables containg data of 5 Russian speakers: "Russian.r1.*", "Russian.r2.*", and so on.
You could read "Russian.r1.*" as all data of "Russian" speaker "r1".
[TOP]
Plotter:
Draws scatterplots with or without confidence ellipses.
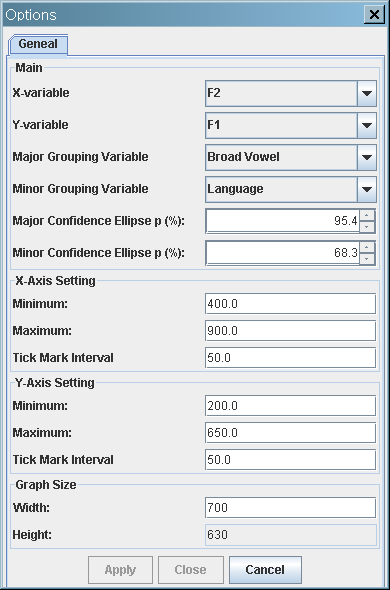
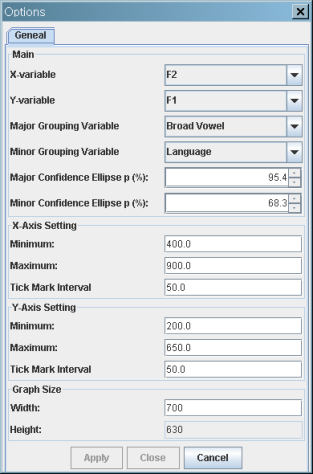
F2 vs. F1 scatterplot with confidence ellipses
- Major confidence ellipses: Two "Broad Vowels":
- /u/ is a collapsed vowel of Korean /우/ and Russian /у/;
- /o/ is a collapsed vowel of Korean /오/ and Russian /о/.
- Minor confidence ellipses: Korean vs. Russian
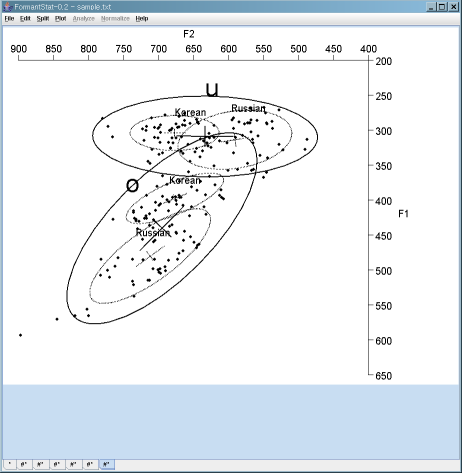
[TOP]
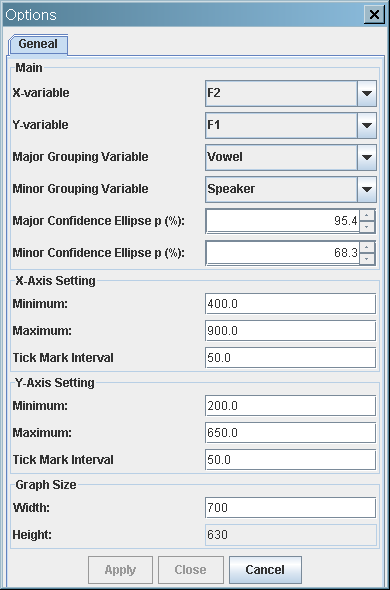
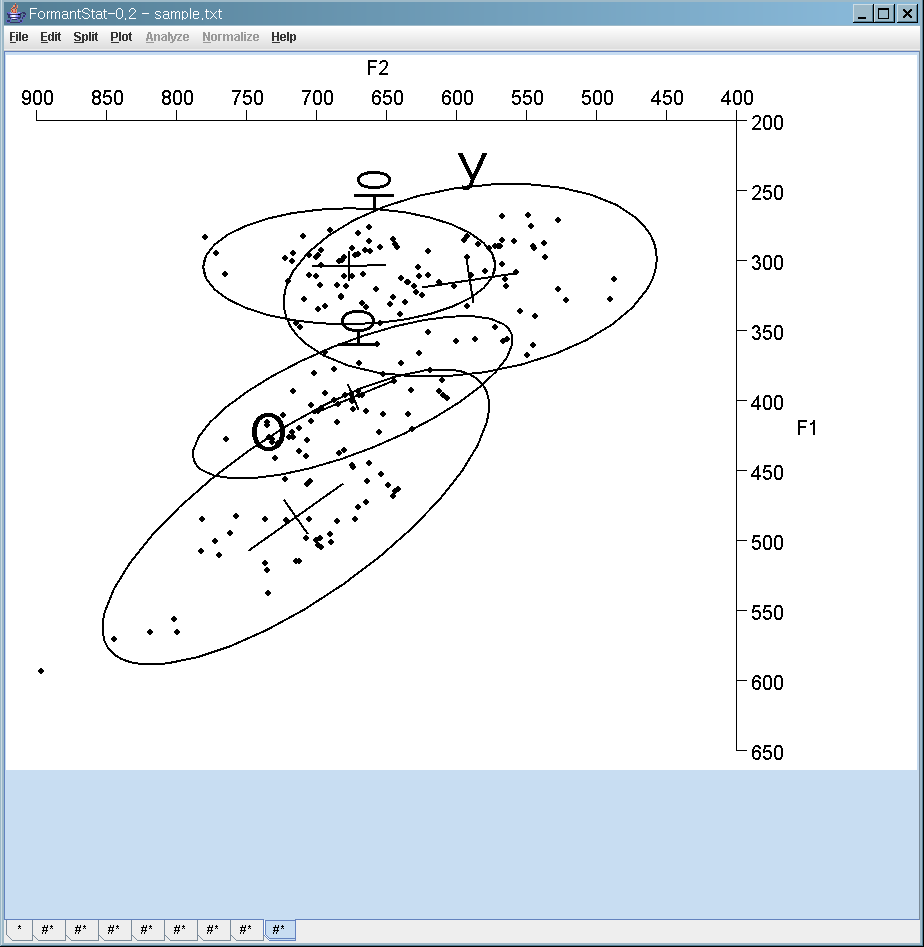
F2 vs. F1 scatterplot with confidence ellipses
- Major confidence ellipses: Four "Vowels" - Korean /우/ and Russian /у/; Korean /오/ and Russian /о/
- Minor confidence ellipses: Five Korean and five Russian Speakers. Each major confidence ellipse bounds five minor speaker ellipses.

You can draw major ellipses without minor ellipse:
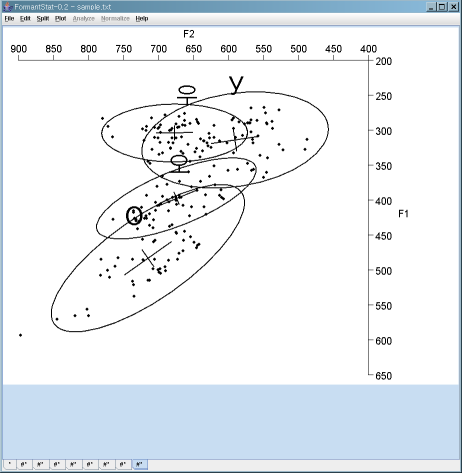
[TOP]
F2-F1 vs. F1 scatterplot with confidence ellipses
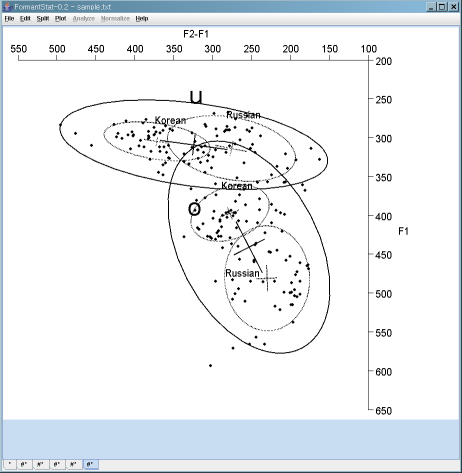
[TOP]
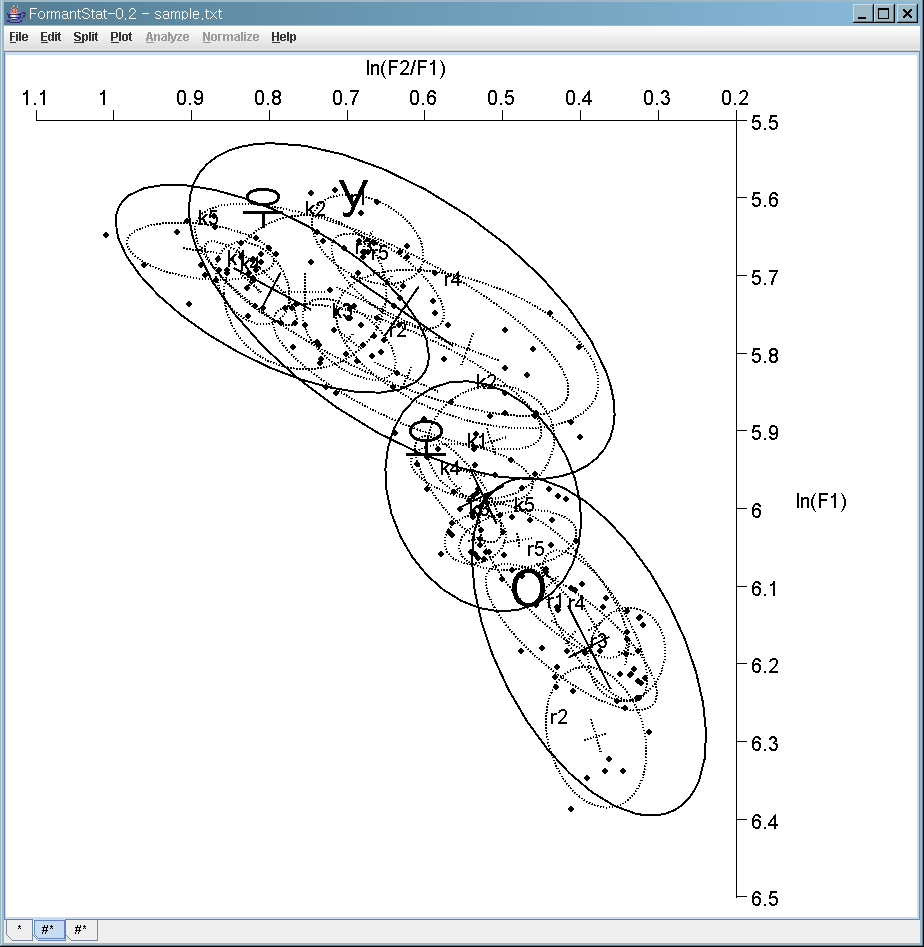
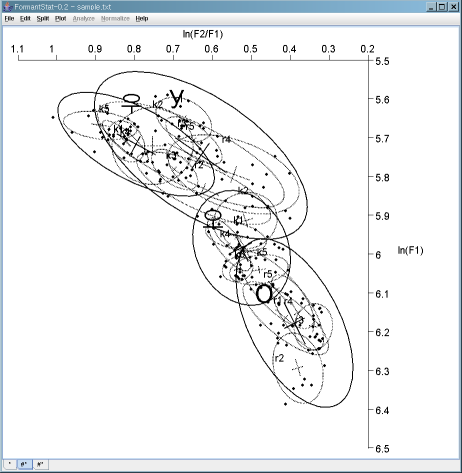
ln(F2/F1) vs. ln(F1) scatterplot with confidence ellipses
The natural logairthm ln is the logarithm having base e = 2.7182...

Without minor ellipse:
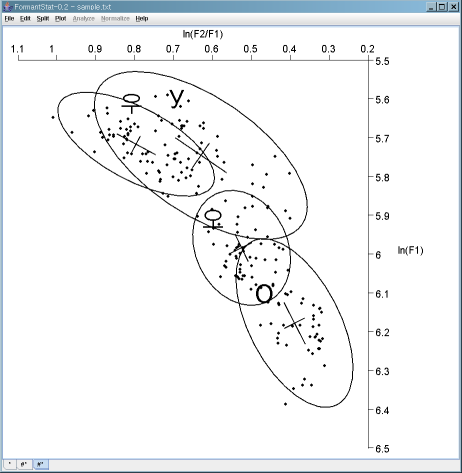
[TOP]
ln(F2/F1) vs. ln(F1) scatterplot with confidence ellipses


Analyzer: basic statistics and more
Not yet implemented!
Noramlizer: speaker normalization
Not yet implemented!